
ArXiv
Preprint
Source Code
Github
How to fix multiple issues with diffusion model weights?
Text-to-image models suffer from various safety issues that may limit their suitability for deployment. Previous methods have separately addressed individual issues of bias, copyright, and offensive content in text-to-image models. However, in the real world, all of these issues appear simultaneously in the same model.
In this paper, we present a method that tackles those diverse issues with a single approach. Our method, Unified Concept Editing (UCE), edits the model without training using a closed-form solution conditioned on cross attention outputs, and scales seamlessly to concurrent edits on text-conditional diffusion models. UCE enables direct editing of concepts based on phrases and attributes without use of new training data, supporting rapid iteration. Key advantages versus finetuning approaches include: efficient scaling of editing multiple concepts, precise concept changes through direct modification of model weights, avoidance of interference with protected or unrelated concepts, and rapid iteration from fast closed-form editing

Why debias/erase/moderate concepts from diffusion models?
Since large-scale models like Stable Diffusion are trained on massive datasets, they often learn concerning capabilities like generating nudity or imitating styles/content without permission. This has created risks: Stable Diffusion can be used to generate nonconsensual deepfake porn, mimic artists' work, reproduce copyrighted/trademarked content, and amplify stereotypes about race and gender. Such issues pose serious challenges for institutions releasing models.
There are methods that address these concerns separately, but they do not scale well to editing multiple concepts together. We propose a closed-form solution that can address these challenges in a unified way at scale, editing multiple concepts concurrently with minimal interference.
How to edit concepts simultaneously in diffusion models?
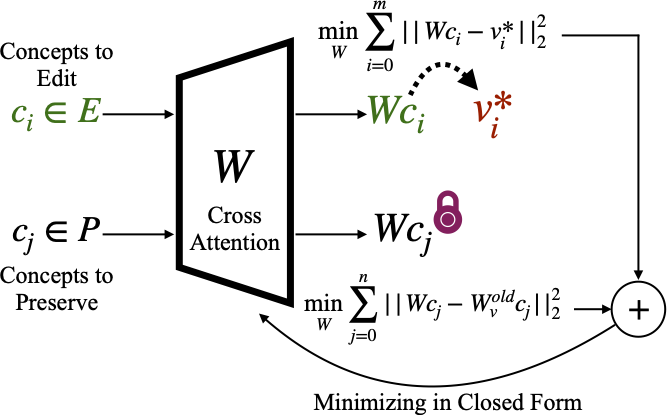
We edit the cross attention weights by conditioning new target output for the concept embeddings to edit and preserve the previoud outputs for concepts to preserve. We minimize the loss shown in the figure above through this closed-form update:
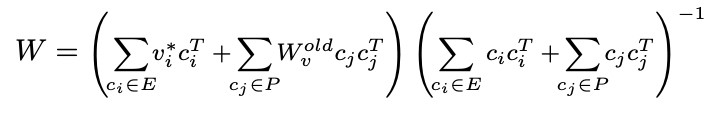
Our method generalizes previous state-of-the-art model editing methods like TIME and MEMIT. Our method can also be generalised to editing any linear projection.
Erasing an artistic style
Models like Stable Diffusion can mimic the styles of more than 1500 artists. Not all artists are excited about their art being mimicked by genrative models and wish to be opted-out of these models' vocubulary. Recent works have been working on filtering the training data to accomodate the opt-out requests from individuals. Eventhough such filtering would exclude the artists from future models that are trained on the filtered dataset, model editing may still be needed for certain artists that aren't fully addressed. We propose using UCE that is scalable, fast, and displays minimal interference with other artists. To erase style, we use the name of the artist and steer them towards general prompts like "art" or "".




Debiasing a profession across gender and race
Previous debiasing methods address only dual attributed biases, however, attributes like race are multi-faceted. We propose a multi-faceted debiasing formulation that can be scaled for multiple concepts. Our method has strong debiasing results, improving the race and gender representation in diffusion models.
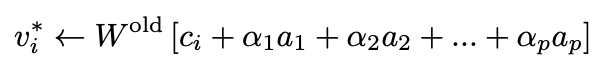
This formulation allows UCE to address multi-attribute biases like race. We show some quantitative results of our method displaying improved race and gender diversity.





Moderating an unsafe concept
We test our method on moderating unsafe concepts like "nudity". We compare our method with ESD-u and ESD-x. We find that our method has similar performance as ESD-x when erasing a single concept, but our method shows minimal interference with other concepts in the model. We also see that moderating multiple unsafe concepts like "harm, violence, child abuse, blood, nudity", our method shows a stronger moderation effect on the model as seen in the figure below.

How to cite
The paper can be cited as follows.
bibliography
Rohit Gandikota, Hadas Orgad, Yonatan Belinkov, Joanna Materzyńska, David Bau. "Unified Concept Editing in Diffusion Models." in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) 2024.
bibtex
@inproceedings{gandikota2024unified,
title={Unified Concept Editing in Diffusion Models},
author={Gandikota, Rohit and Orgad, Hadas and Belinkov, Yonatan and Materzy{\'n}ska, Joanna and Bau, David},
booktitle={Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision},
year={2024},
note={arXiv:2308.14761}
}